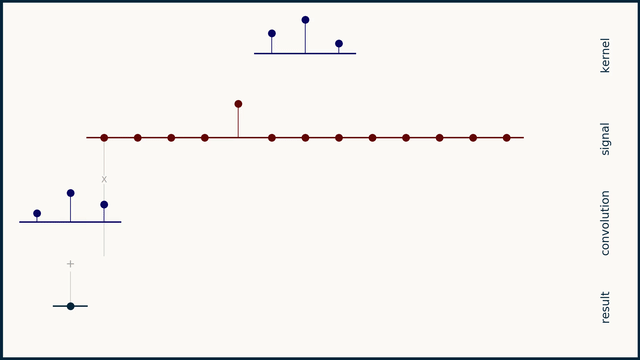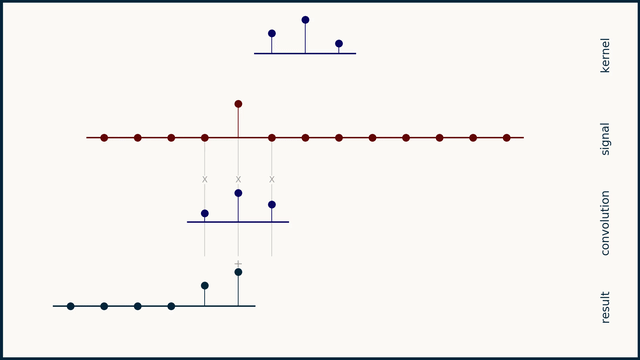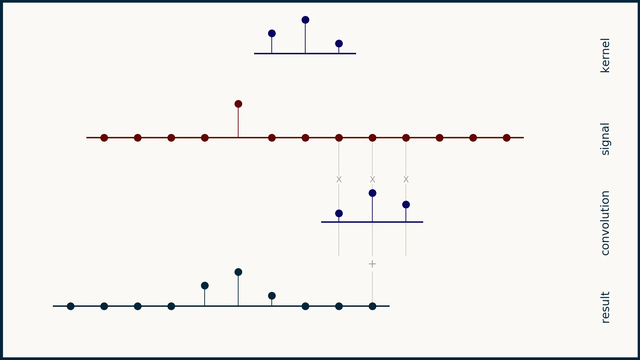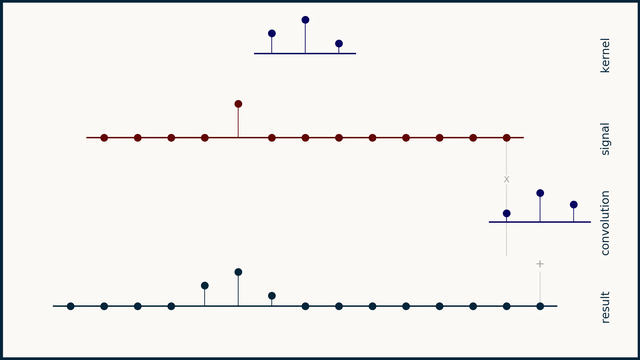
Before going into the code and compute profiles for a 1D convolution kernel, lets take a step back to quickly go over what a 1D convolution is. Note: if you have the time, watch ThreeBlueOneBrown's video on convolutions, it's much better than what I have here! Convolution involves taking an input vector (or matrix in the 2D case), a kernel, and sliding the kernel over the input vector while taking a vector dot product between the two at each step. Depending on the kernel values this can result in many useful outputs, such as the average value in the window at each step (if each element in the kernel is 1/kernel_length), or a Gaussian blur (if the kernel is normally distributed).
See here, for the original animation and pairing explanation.
Of course in our case the kernel values are learned and represent values that achieve the lowest loss on the training set. Important parameters for a 1D convolution are
Typically the weight tensor for each 1D Conv layer has format (output_channels, input_channels, kernel_size) and bias is a vector of the same length as the number of output_channels. You can visualize each output_channel being calculated as the result of a kernel of size (input_channels, kernel_size) sliding over the input of size (input_channels, input_length).
Our first pass at a GPU kernel will involve mapping blocks/threads as follows.
With this partitioning of work in mind, lets dive into the CUDA code. We start by templating a handful of variables so we can flexibly dispatch a function call to the right kernel at run-time. CUDA support for dynamic memory allocation is a bit tricky, so I have typically used template arguments for this. The function definition is pretty straight forward, taking in pointers to relevant inputs and an integer for the number of input channels. We don’t need to make input_channels a templated parameter because it doesn’t get used for memory allocation. We define two constant integers that we will refer to throughout the program: padded_input_length and weight_offset. Padded input length is the sum of input_length and double the padding (since we pad the front and back of the input vector). Weight offset is an integer that calculates the offset within the weight tensor for this block. Since each output_channel has its own chunk of memory that is input_channels * KernelSize in length, we offset by this distance times the output_channel that this block is responsible for (blockIdx.x).
template <int InputChannels, int InputLength, int Padding, int KernelSize>
__global__ void conv1d_naive(float *d_input, float *d_weight, float *d_bias, float *d_output)
{
//define constants
const int padded_input_length = InputLength + 2 * Padding;
const int weight_offset = blockIdx.x * InputChannels * KernelSize;
//allocate register memory
float regInput[padded_input_length] = {0};
float regKernel[KernelSize];
Next, we load the input vector and kernel associated with the work this thread is responsible for. We start by allocating thread registers of size padded_input_length, and KernelSize. The next two loops initialize the registers that store the input vector with 0s, and then load the relevant input from global memory. The last loop loads the weights into registers assigned to the kernel for this row.
//allocate register memory
float regInput[padded_input_length] = {0};
float regKernel[KernelSize];
//load input tensor from global memory into thread registers
for(int inputIdx = 0; inputIdx < InputLength; ++inputIdx){
regInput[Padding + inputIdx] = d_input[threadIdx.x * InputLength + inputIdx];
}
//load convolution kernels from global memory into thread registers
for(int kernelIdx = 0; kernelIdx < KernelSize; ++kernelIdx){
regKernel[kernelIdx] = d_weight[weight_offset + threadIdx.x*KernelSize + kernelIdx];
}