KV caches are one of the most critical techniques for efficient inference in LLMs in production. KV caches are an important component for compute-efficient LLM inference in production. This article explains how they work conceptually and in code with a from-scratch, human-readable implementation.
It's been a while since I shared a technical tutorial explaining fundamental LLM concepts. As I am currently recovering from an injury and working on a bigger LLM research-focused article, I thought I'd share a tutorial article on a topic several readers asked me about (as it was not included in my Building a Large Language Model From Scratch book).
Happy reading!
Overview
In short, a KV cache stores intermediate key (K) and value (V) computations for reuse during inference (after training), which results in a substantial speed-up when generating text. The downside of a KV cache is that it adds more complexity to the code, increases memory requirements (the main reason I initially didn't include it in the book), and can't be used during training. However, the inference speed-ups are often well worth the trade-offs in code complexity and memory when using LLMs in production.
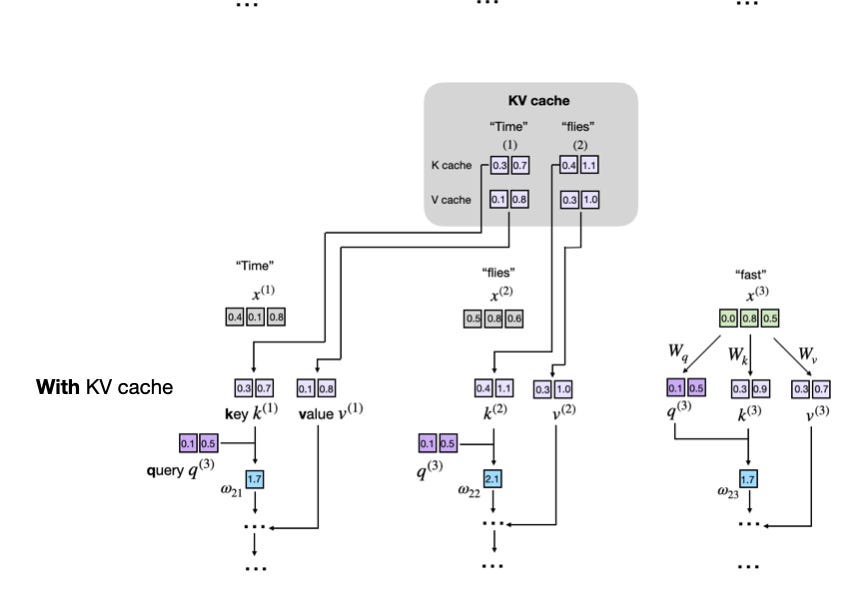
What Is a KV Cache?
Imagine the LLM is generating some text. Concretely, suppose the LLM is given the following prompt: "Time". As you may already know, LLMs generate one word (or token) at a time, and the two following text generation steps may look as illustrated in the figure below:

The diagram illustrates how an LLM generates text one token at a time. Starting with the prompt "Time", the model generates the next token "flies." In the next step, the full sequence "Time flies" is reprocessed to generate the token "fast".
Note that there is some redundancy in the generated LLM text outputs, as highlighted in the next figure:

This figure highlights the repeated context ("Time flies") that must be reprocessed by the LLM at each generation step. Since the LLM does not cache intermediate key/value states, it re-encodes the full sequence every time a new token (e.g., "fast") is generated.
When we implement an LLM text generation function, we typically only use the last generated token from each step. However, the visualization above highlights one of the main inefficiencies on a conceptual level. This inefficiency (or redundancy) becomes more clear if we zoom in on the attention mechanism itself. (If you are curious about attention mechanisms, you can read more in Chapter 3 of my Build a Large Language Model (From Scratch) book or my Understanding and Coding Self-Attention, Multi-Head Attention, Causal-Attention, and Cross-Attention in LLMs article).
